随着大数据时代的到来,数据架构经历了从单体系统到分布式流处理框架的深刻演变。本文将以数据处理服务为主线,系统梳理这一变革过程,帮助读者深入理解数据架构的发展脉络。
一、单体数据架构时代
在早期,数据处理多依赖于单体架构,如单一数据库或传统数据仓库。这类系统将所有数据处理逻辑集中在一个应用中,结构简单、易于部署。随着数据量的激增和实时性要求的提高,单体架构暴露出扩展性差、容错能力弱、难以支持复杂流处理等瓶颈。例如,在高并发场景下,系统容易成为性能瓶颈,且故障时可能导致整个服务瘫痪。
二、分布式数据架构的兴起
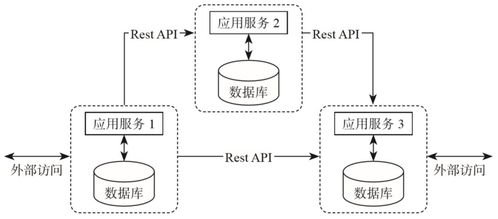
为应对单体架构的不足,分布式数据架构逐渐普及。这一阶段出现了批处理系统(如Hadoop MapReduce)和早期的流处理框架(如Storm)。Hadoop通过分布式存储和计算实现了海量数据的离线处理,但延迟较高;Storm则支持实时流处理,但缺乏精确一次语义和状态管理能力。分布式架构提升了扩展性和容错性,但架构复杂,运维成本增加,且批流分离导致数据一致性挑战。
三、Flink与现代流处理革命
Apache Flink作为新一代流处理引擎,标志着数据架构的重大演进。Flink以流处理为核心,统一了批处理和流处理模型,提供低延迟、高吞吐和精确一次语义。其特点包括:
- 状态管理:支持有状态计算,便于处理复杂事件流。
- 容错机制:通过检查点和保存点确保数据一致性。
- 灵活部署:可运行于YARN、Kubernetes等环境,适应云原生趋势。
Flink广泛应用于实时数据分析、欺诈检测和物联网数据处理等领域,推动了数据处理服务向实时化、智能化发展。
四、数据处理服务的未来展望
数据架构的演变驱动数据处理服务不断升级。未来趋势包括:
- 湖仓一体化:结合数据湖的灵活性和数据仓库的管理能力。
- AI集成:将机器学习与流处理深度融合,实现智能实时决策。
- 云原生优化:基于容器和微服务,提升弹性与可观测性。
从单体到Flink,数据架构的演变不仅是技术的迭代,更是业务需求的映射。企业需根据场景选择合适架构,以构建高效、可靠的数据处理服务,赋能数字化转型。